Approaching a Scripting Task
Introduction: The Challenge 

Your research team just caught wind that you know Python. They have some ARGOS tracking data - a text file in a marginally human readable format and with a lot of “noise” - and they want you to build a tool that will parse this data into a format whereby a user can enter a date and retrieve the location at which the turtle was found.
With some trepidation, we accept this challenge. It’s a great opportunity for us to apply the concepts we learned in the last section, namely Python syntax, variables & objects, properties & methods, data structures, etc. It’s also a great opportunity to learn how these elements are assembled into a coherent and effective workflow, i.e., writing a Python script.
In this first session, we examine how to approach a scripting task. Writing code is somewhat like translating human ideas into computer logic, and some simple techniques will make that process easier.
Learning Objectives
On completion of this lesson, you should be able to:
- Articulate an example task where Python is helpful
- Develop pseudocode for an example task
- Dissect your pseudocode into a coding workplan
- Prepare a coding workspace
Background - The Overall Task
SeaTurtle.org posts tracking data for various individual turtles. These data are in a somewhat raw format derived from ARGOS satellite tracking systems. I have downloaded data for an adult loggerhead turtle, Sara, and our task is to develop code that can interpret Sara’s raw tracking data. Specifically, we want to allow a user to specify a date and have our code report where Sara was seen on that date.
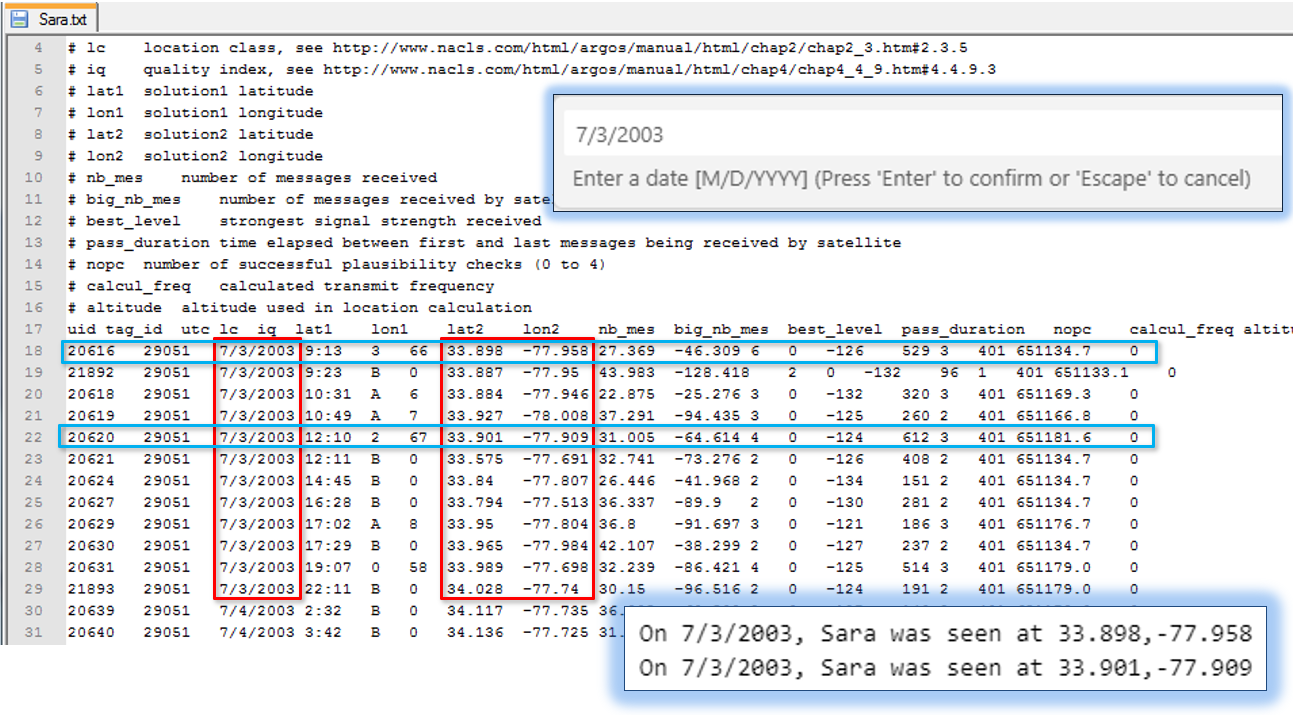
Tackling this task requires some understanding of the raw ARGOS data, both its format and the data reported. We will discuss this in class and later in this lab. However, you can see in the figure above, that all the information needed to do this task is in the Sara.txt file; we just need to develop code to extract exactly the data we want and report it.
Resources
- Tracking data for Sara the turtle: sara.txt (Right-click and save the file…)
- A page listing the raw code for specific tasks in this exercise is here.
- A link to a finished Git repository for this project is here: https://github.com/ENV859/TurtleTest
Step 1. Generating pseudocode
The context of this exercise is as follows: We have obtained data in a standard format, in this case ARGOS tracking data. We want to write a script that can read any ARGOS tracking data set, extract records matching a date specified by the user, and report the location of any observations made at that date. Reported observations must also meet quality criteria using tags included in the ARGOS dataset.
Such a script requires many steps, and to take on all the steps at once is a daunting task. Therefore, we first consider the pseudocode of the exercise, that is, the logical steps involved in meeting our objective given our inputs. In generating pseudocode, we don’t have to know the exact Python commands we’ll implement; we just want to identify the key steps. It’s quite possible we’ll revise some of our pseudocode when actually implementing it, but sketching things out is nonetheless a useful first step in writing a script of any complexity.
Generating pseudocode can be more art than science and gets easier the more you understand particular coding environment. (Think about how much better you are at putting together geoprocessing models now than when you first started learning ArcGIS…) In other words, it may not come naturally at first, but with practice you’ll get better. I’ve listed the pseudocode for this exercise below:
» Task 1.1: Develop pseudocode for your project
-
Open the ARGOS data file
-
Read and parse each line
a. Skip comment lines
b. Skip records below a quality threshold (qc <> 1, 2, or 3)
c. Add observation date to a date dictionary, keyed by the observation UID
d. Add observation lat./long. to a location dictionary, keyed by the observation UID
-
Allow user to specify date
a. Inform if date is invalid
-
Identify keys in date dictionary matching user supplied date
-
Identify values in location dictionary with keys found above
-
Print information to screen
Step 2. Devising a plan of attack…
The pseudocode we developed in Step 1 is a blueprint, but not a construction plan.
The next step, therefore, is to map out a sequence - going from simple to more involved - of putting the necessary steps together. The idea here is to isolate the tasks involved in the script into discrete steps such that each step can be built, and debugged in sequence. If we do too much at once and it doesn’t work, we’ll spend more time figuring out where it went wrong. However, if we start simple and something goes awry, our debugging is more confined.
Determining an appropriate sequence for tackling a project is a bit of an art form, one that you improve with more experience and comfort with the coding language. The general idea, however, is start with a very simple task and add complexity. For example, if you are going to iterate through a chunk of sub-code, first get the chunk of sub-code working, and then add the iteration.
A more relevant example for us is the fact that we need to read text in from a file, and for each line of text in this file, split it into a list of values, and then work with each value. That in itself seems like a tall order, but if we start with just a line of text copied from the data file and pasted into our code - by us, not via Python command - we can tackle the simpler task of parsing that string into a list.
With that in mind, the sequence I suggest we take is as follows:
| Sequence | Task |
|---|---|
| 1. | Parse a single line of tracking data into variables |
| 2. | Read a single line of tracking data from the file into Python (and then parse into variables) |
| 3. | Read in all lines of tracking data from a file into Python (and then parse into variables) |
| 4. | While reading in all lines of tracking data, add variables into dictionaries of values |
| 5. | Add conditional statements so only valid values are added to the dictionaries. |
| 6. | From our dictionaries, extract data for a selected date. |
| 7. | All the user to specify the date used to select data from our dictionary |
| 8. | Add code to handle if the user enters an improper date |
There are certainly other ways of going about this, but I’m hopeful you’ll at least see and appreciate the utility of breaking a scripting objective down into sub tasks can really help in writing complex scripts. We will also, almost certainly, deviate from this sequence as we encounter unexpected glitches or possibly improved pathways to our goal. Still, it’s always useful to start with a plan, one that goes from simple to complex.
I should also add that we will encounter plenty of tasks that we have not covered so far (e.g. reading data from a file?!?). But this provides a great way to learn Python - by doing!
Next up, we will embark on writing code to get this done. But first, we are going to explore a technology that is going to greatly assist us as we bumble through lots and lots of mistakes in getting there, namely Git and GitHub.